
Task One:
This section goes over a quick explanation of Google as a search engine and website indexer, that uses spiders/crawlers to gather keywords and website urls to make a dictionary on websites to suggest when using the search engine.
ANS 1 : There is nothing needed to be done. Press complete and away we go!
Task Two:
This section explains the use of crawlers and the “How” a website is indexed.
Hint: Your best way of solving these questions is using ctrl+f, which will bring up a word finder, and search the webpage for keywords or clues of the question being asked.
Question 1: Name the key term of what a “Crawler” is used to do
The first answer can be found reading this paragraph or (ctrl+f) searching for the word “crawler” and seeing what sentences contains a word that is the answer:

ANS 1: index
Question 2: What is the name of the technique that “Search Engines” use to retrieve this information about websites?
This answer is a little harder to find and requires you to crawl the paragraphs yourself looking for the quotation key word “Search Engine” hint that the question is offering.

ANS 2: crawling
Question 3: What is an example of the type of contents that could be gathered from a website?
Searching for the word “content” will help with this answer. The question has a couple of possible answers of the type of content that can be gathered from a website. It could be urls to other websites posted on the crawled website, could be information on specific subjects, or keywords.
ANS 3: keywords
Task Three
This section goes over SEO and how websites can be ranked by the amount of keywords and hashtags that it meets in searchability for users, social media, and search engines.
These questions will require using the site: https://seositecheckup.com/ and using tryhackme.com to find the answers.
Link for test: https://seositecheckup.com/seo-audit/tryhackme.com
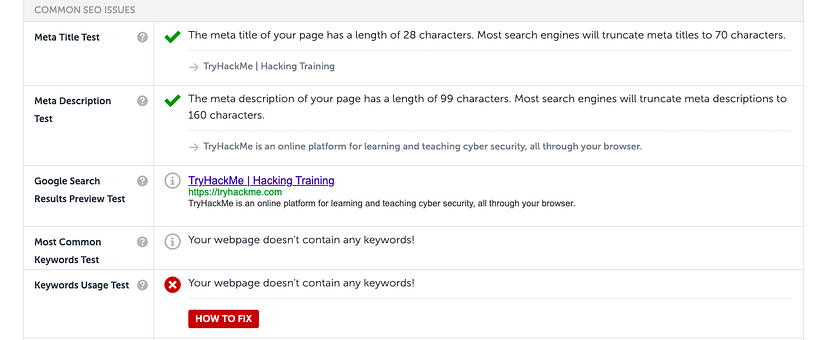
Question 1: Using the SEO Site Checkup tool on “tryhackme.com”, does TryHackMe pass the “Meta Title Test”? (Yea / Nay)
Check out the websites’ description Meta Title Test. Result has a passing green check mart
ANS: Yea
Question 2: Does “tryhackme.com” pass the “Keywords Usage Test?” (Yea / Nay)
The website has a red x mark meaning it did not pass the Keywords Usage Test and says there are not any keywords used.4
ANS: Nay
Question 3: Use https://neilpatel.com/seo-analyzer/ to analyse https://blog.cmnatic.co.uk: What “Page Score” does the Domain receive out of 100?
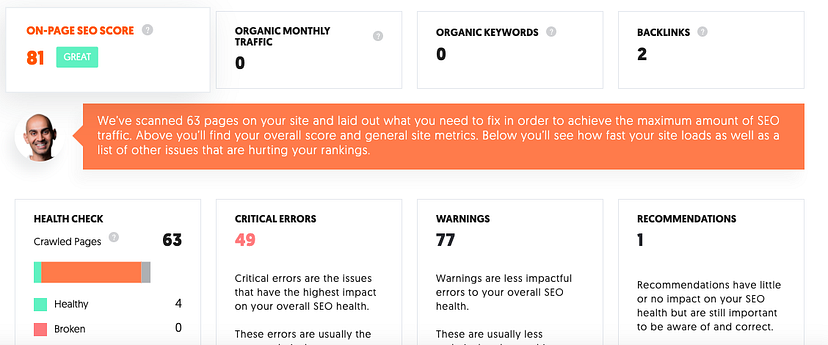
Look at the On-Page SEO Score
ANS: 81/100
Question 4: With the same tool and domain in Question #3 (previous): How many pages use “flash”?
Don’t see anything mentioning flash, or Adobe flash, so I am going with 0.
ANS: 0
Question 5: From a “rating score” perspective alone, what website would list first? tryhackme.com or blog.cmnatic.co.uk
The site — tryhackme had a score of 62, while blog.cmnatic.co.uk has a score of 81
ANS: blog.cmnatic.co.uk
Task Four
This section goes over Robots.txt and which file directories on a sitemap can be allowed or disallowed to be indexed by crawlers(and also can be limited to which crawlers can access these directories like if it is google or a bing crawler).
Question 1: Where would “robots.txt” be located on the domain “ablog.com”
When a site is first being accessed by crawlers, there will be a page where information is hidden under, and that is often in the directory/text file called “ robot.txt “ which will hold the sitemap for crawlers to get the index they want to yoink
ANS: ablog.com/robots.txt
Question 2: If a website was to have a sitemap, where would that be located?
The sitemap is the file that will hold an xml format file with the website’s index for crawlers to use.
ANS: sitemap.xml
Question 3: How would we only allow “Bingbot” to index the website?
This requires using the code that is mentioned in the lesson of User-Agent, and the specific crawler allowed instead of All which would be *

ANS: User-Agent: Bingbot
Question 4: How would we prevent a “Crawler” from indexing the directory “/dont-index-me/”?
Using the lesson example to solve this question of limiting a index directory

ANS: Disallow: /dont-index-me/
Question 5: What is the extension of a Unix/Linux system configuration file that we might want to hide from “Crawlers”?
The hint for this says “system files are usually 3/4 characters!” so that means the configuration file extension is slightly short than the usual abbreviation of config
ANS: .conf
Task Five
This section is pretty self explanatory after reading the first few paragraphs of this lesson.
Question 1: What is the typical file structure of a “Sitemap”?
As mentioned in a previous lesson, if you look at the file format for “/sitemap.xml “, it uses a xml format
ANS: xml
Question 2: What real life example can “Sitemaps” be compared to?
The sitemap is the map to help the little crawlers to not get lost on a website.
ANS: map
Question 3: Name the keyword for the path taken for content on a website
The first explanation of routes are in the lesson’s sentence “The blue rectangles represent the route to nested-content, similar to a directory I.e. “Products” for a store.”
ANS: route
Task Six
Now to the meat of the whole “Google Dorking”/Google Fu by using the index categorizations for websearches that Google has meticulously gathered. All those crawlers can now be used in reverse uno fashion for your speedy research.


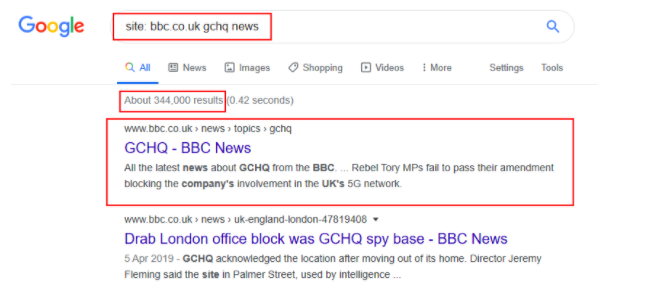
Question 1: What would be the format used to query the site bbc.co.uk about flood defences?
You want to use the tag [index:] the website [bbc.co.uk] and the topic [flood defences]
ANS: site: bbc.co.uk flood defences
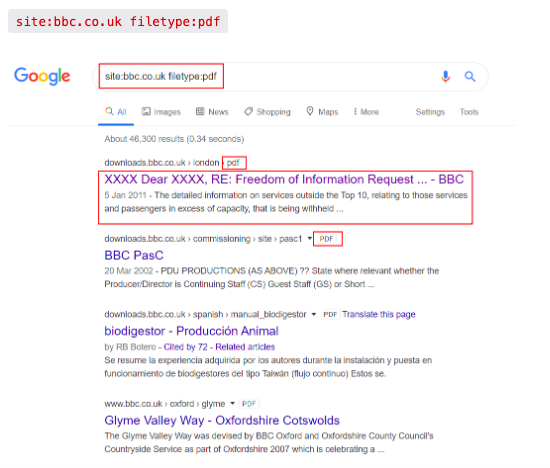
Question 2: What term would you use to search by file type?
Looking at the chart, filetype: would be the option
ANS: filetype:
Question 3: What term can we use to look for login pages?
The Hint in this says “term: query” so if you think about an intitle on a web address and web page title, it may say website.com/login, or the page title itself may say “login”
*ANS: intitle: login
And, we completed this room as well 🙌